3D-RFT: Reinforcement Fine-Tuning for Video-based 3D Scene Understanding
ICML 2026
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a transformative paradigm for enhancing the reasoning capabilities of Large Language Models (LLMs), yet its potential in 3D scene understanding remains underexplored. Existing approaches largely rely on Supervised Fine-Tuning (SFT), where the token-level cross-entropy loss acts as an indirect proxy for optimization, leading to a misalignment between training objectives and task performances.
To bridge this gap, we present Reinforcement Fine-Tuning for Video-based 3D Scene Understanding (3D-RFT), the first framework to extend RLVR to video-based 3D perception and reasoning. 3D-RFT shifts the paradigm by directly optimizing the model towards evaluation metrics. 3D-RFT first activates 3D-aware Multimodal Large Language Models (MLLLMs) via SFT, followed by reinforcement fine-tuning using Group Relative Policy Optimization (GRPO) with strictly verifiable reward functions. We design task-specific reward functions directly from metrics like 3D IoU and F1-Score to provide more effective signals to guide model training.
Extensive experiments demonstrate that 3D-RFT-4B achieves state-of-the-art performance on various video-based 3D scene understanding tasks. Notably, 3D-RFT-4B significantly outperforms larger models (e.g., VG LLM-8B) on 3D video detection, 3D visual grounding, and spatial reasoning benchmarks. We further reveal good properties of 3D-RFT such as robust efficacy, and valuable insights into training strategies and data impact. We hope 3D-RFT can serve as a robust and promising paradigm for future development of 3D scene understanding.
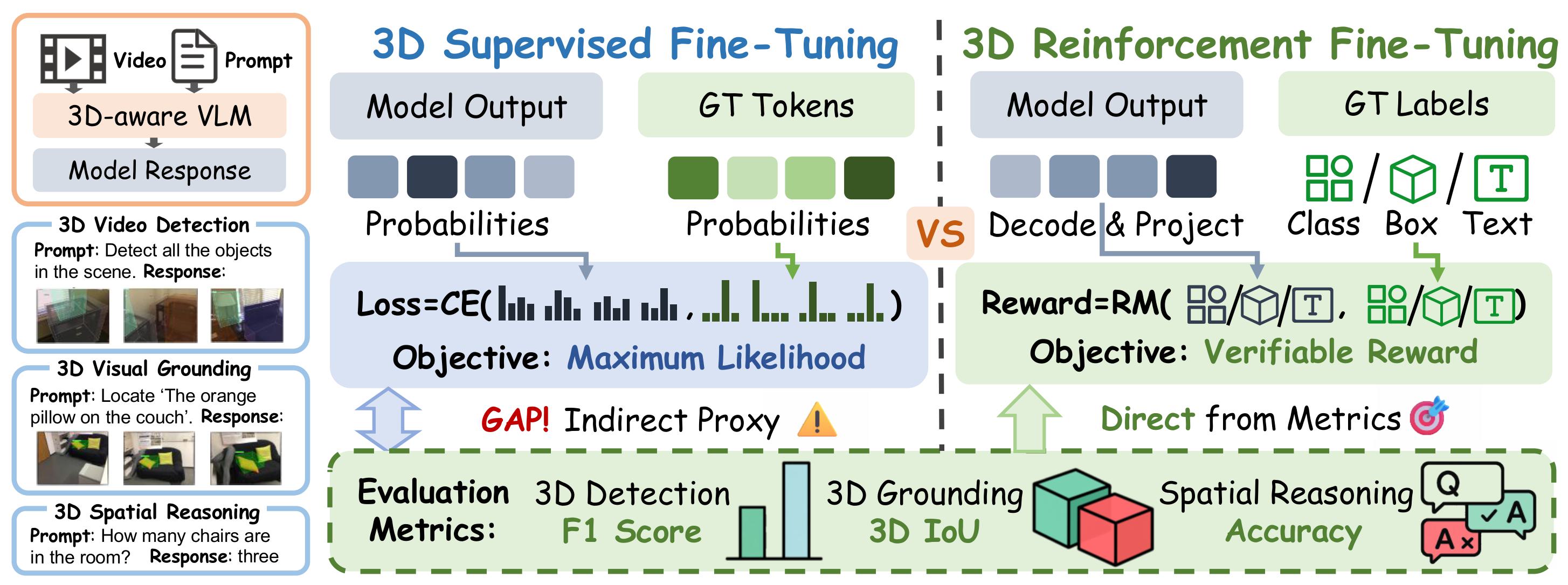
Comparison between SFT and 3D-RFT training paradigms. Left: Standard Supervised Fine-Tuning (SFT) relies on a per-token Cross-Entropy loss which acts as an indirect proxy, leading to a gap between training objectives and final evaluation metrics. Middle: Identical output formats for 3D Video Detection, Grounding, and Spatial Reasoning tasks. Right: 3D-RFT utilizes a Scalar Reward (Policy Gradient) derived directly from evaluation metrics (e.g., F1-Score, 3D IoU, and Accuracy) through a decoding and parsing module, ensuring the model directly optimizes for the final task performance.
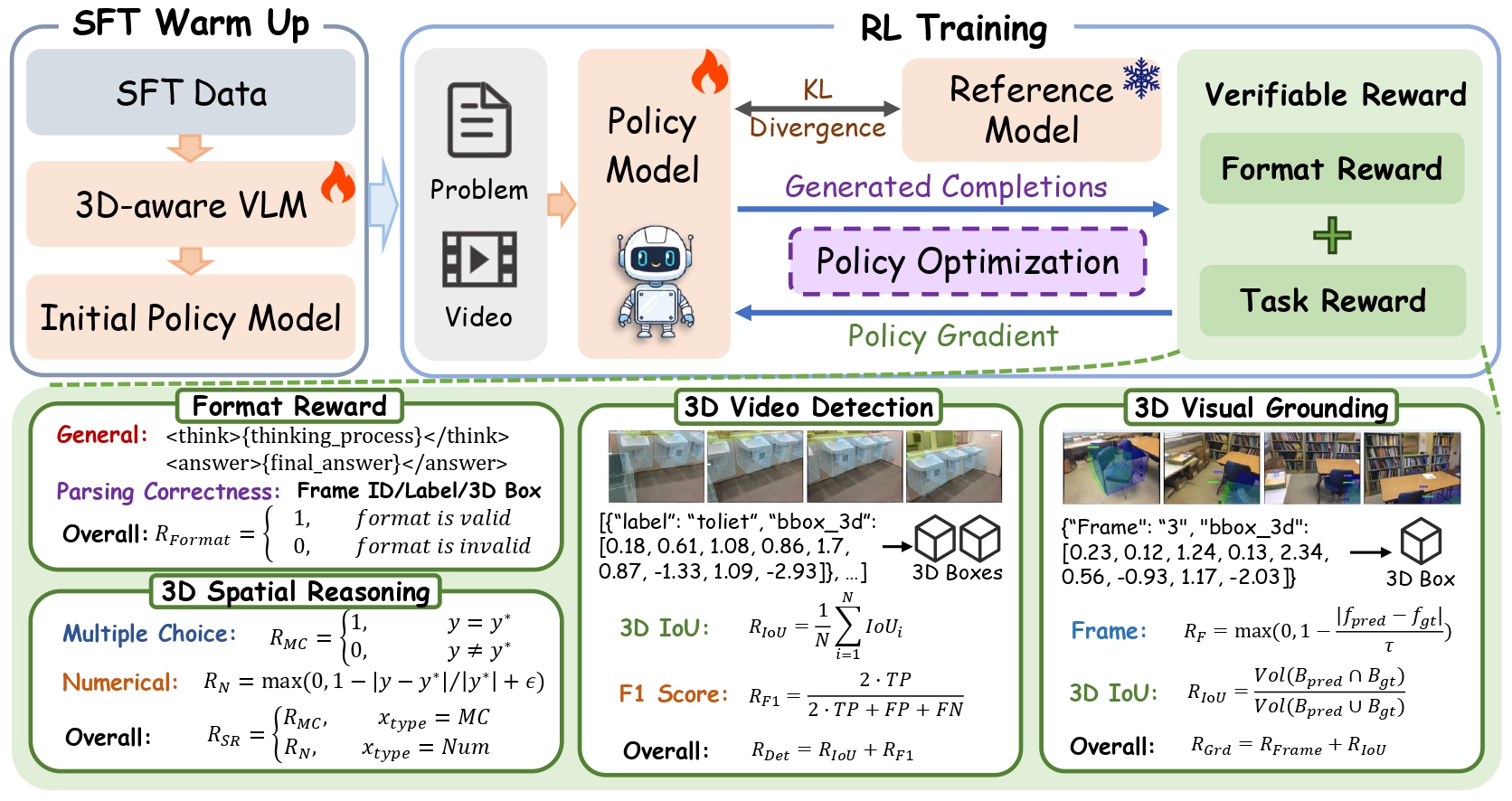
The process consists of two main stages: (1) SFT Warm Up: Initial training of the 3D-aware VLM using SFT data to establish a baseline policy. (2) RL Training: The Policy Model generates completions for video-based problems. A Verifiable Reward is calculated based on Format Reward (adherence to structured output) and Task Reward (performance in 3D Video Detection, 3D Visual Grounding, and Spatial Reasoning using metrics like 3D IoU and F1 Score). The model is optimized via Policy Gradient while maintaining a KL Divergence constraint relative to the frozen Reference Model.
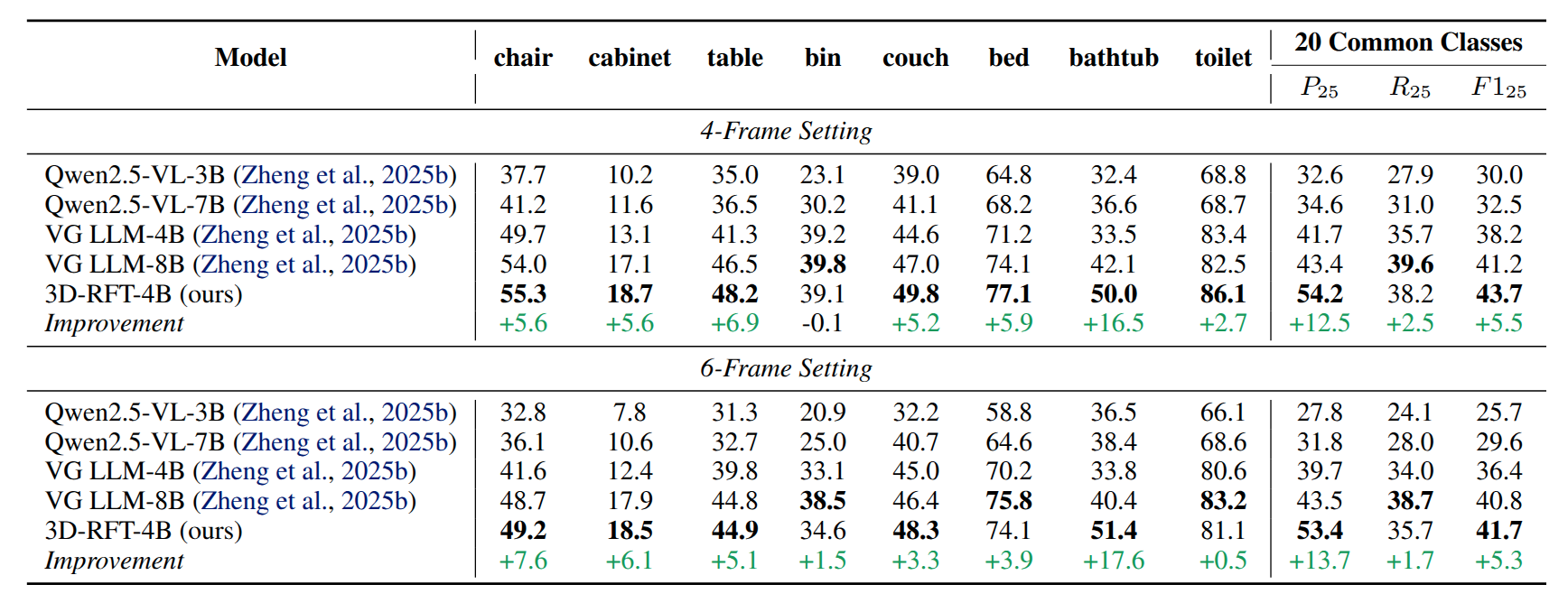
Quantitative results on ScanNetDetection. In this table, we present the comparison with baseline models and report the performance improvement between the SFT baseline (VG LLM-4B) and 3D-RFT-4B (ours). The main conclusions: 1) 3D-RFT-4B significantly enhances detection performance over the SFT baseline. 2) 3D-RFT-4B outperforms the larger VG LLM-8B.
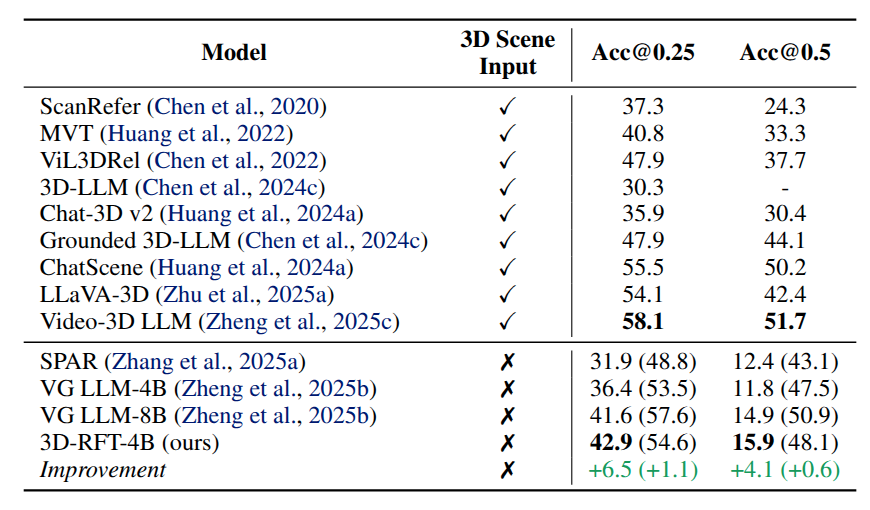
Quantitative results on ScanRefer. The content in “()” indicates results with proposal refinement. The main conclusions: 1) 3D-RFT significantly enhances performance compared to the SFT baseline. 2) 3D-RFT-4B outperforms the larger VG LLM-8B.
Quantitative results on VSI-Bench. We include zero-shot results of base models, and test results of models after SFT and RFT. 3D-RFT consistently improves spatial reasoning performance. Notably, 3D-RFT-4B significantly outperforms some larger models, demonstrating the effectiveness of RFT in optimizing spatial reasoning capabilities.
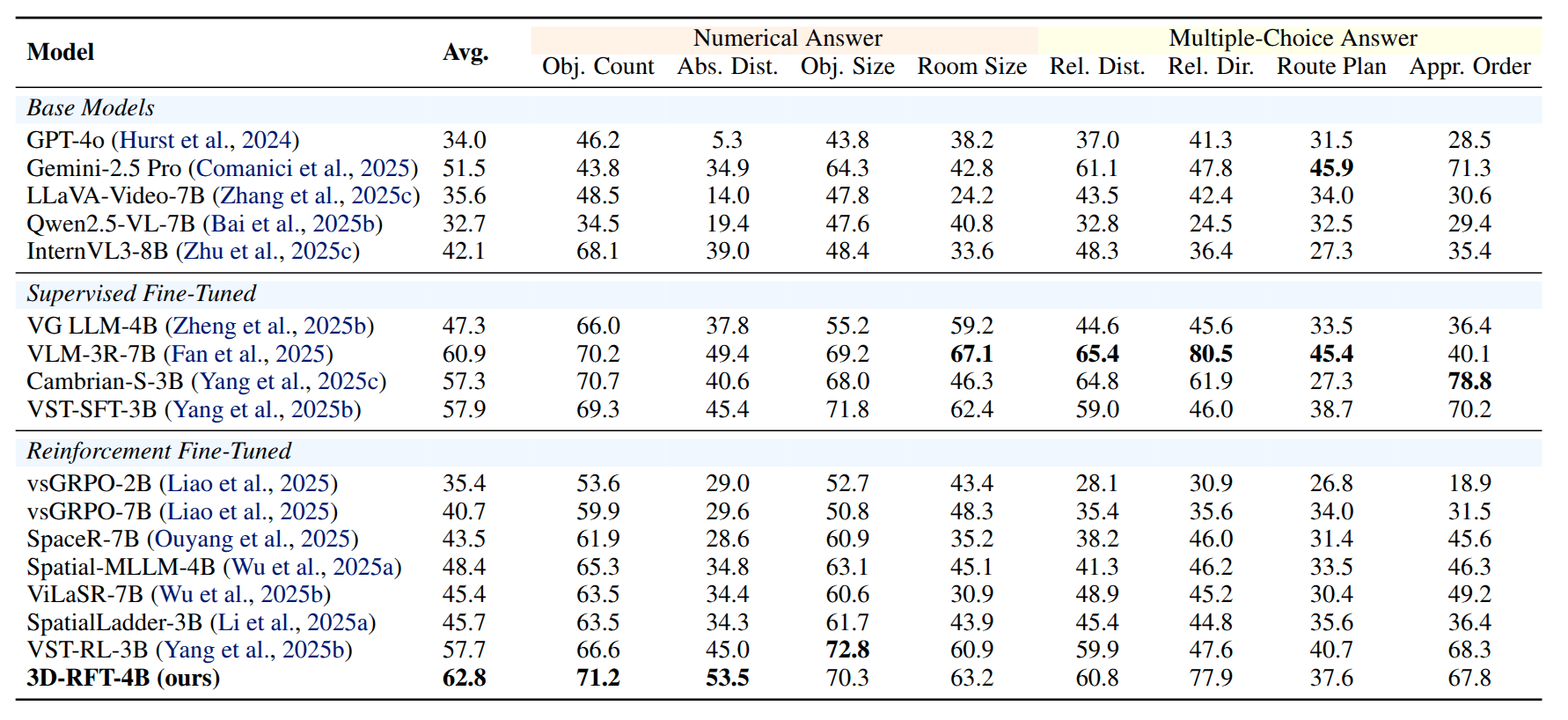
3D-RFT consistently improves spatial reasoning performance. As shown in Fig. 3, we present evaluation results regarding two SFT checkpoints, and compare their performances between “before” and “after” RFT. The results demonstrate that RFT yields consistent improvements on VSI-Bench, especially on TA test. Moreover, RFT on TA task elicits improvements on DA task. In addition, we observe that continually training with SFT yields a moderateperformance drop, which suggests the advantage of RFT.
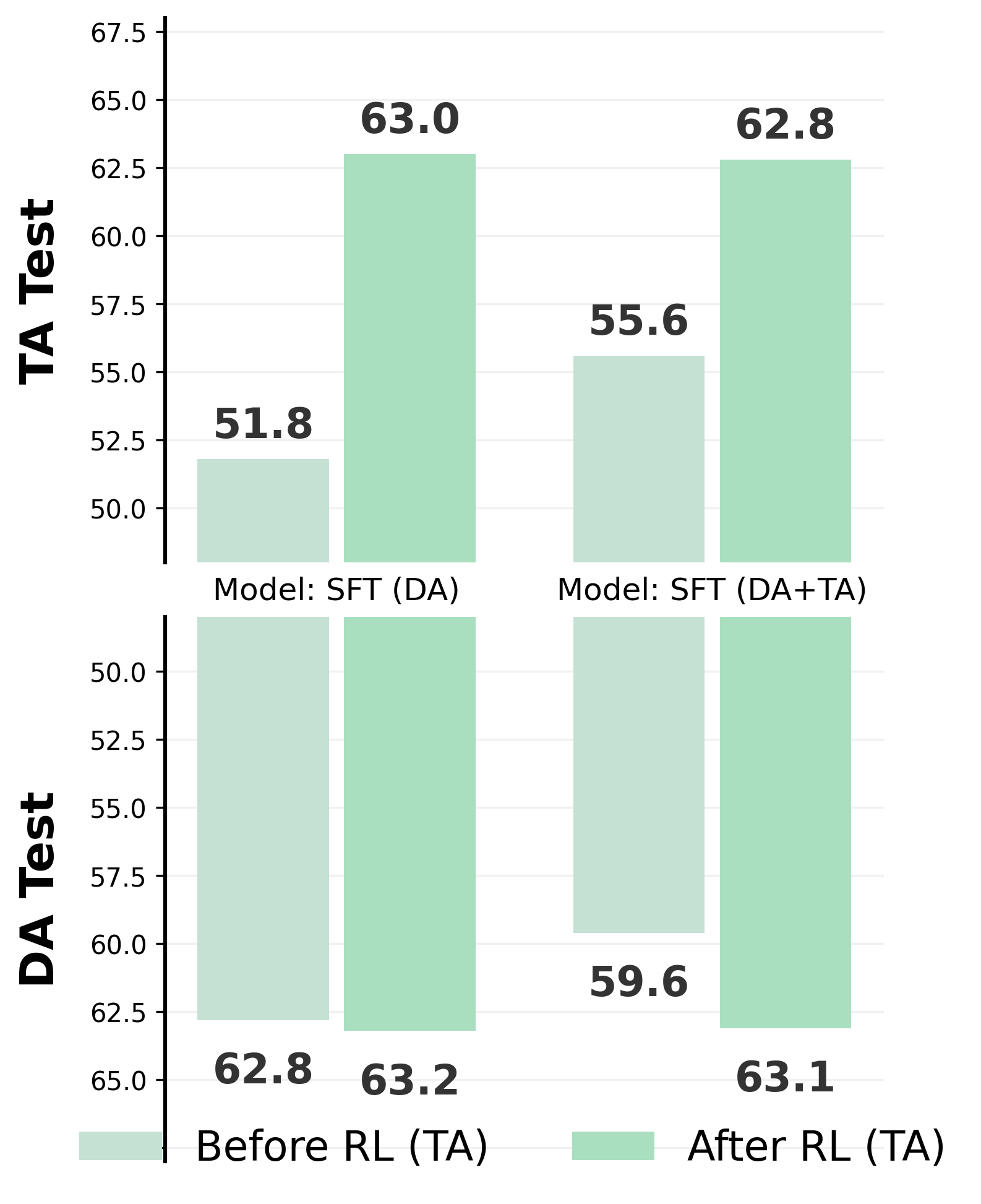
3D Video Detection. The following figure illustrates the training dynamics of 3D-RFT on 3D video detection. The consistent rise in both Evaluation F1 Score (a) and F1 Reward (b) confirms that RFT effectively optimizes perception. Analyzing the reward components reveals a strategic shift: while the global F1 Reward (b) steadily increases, the IoU Reward (c) peaks early and then slightly declines. This indicates the policy transitions from initial geometric refinement (tightening boxes) to recall maximization (reducing false negatives). In the latter phase, the dense IoU Reward serves as a critical regulator, while the sparser F1 Reward optimizes the global balance between precision and recall. Moreover, the continuous improvement at the end implies that RLVR is a stable and effective paradigm for 3D perception tasks.
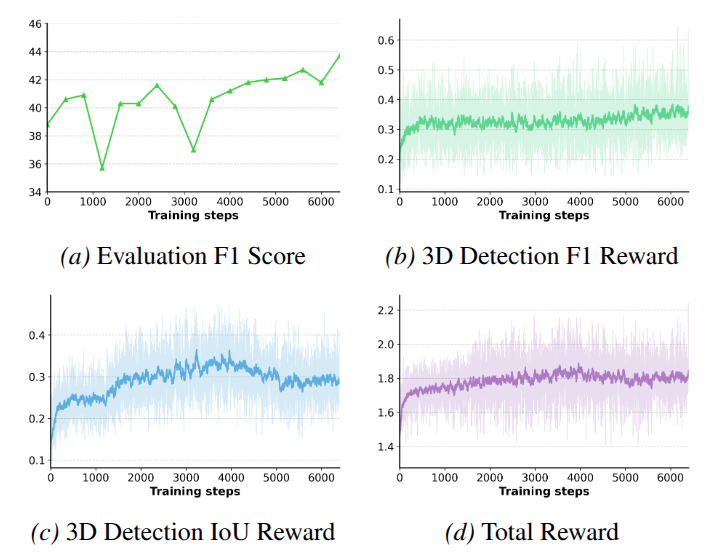
3D Spatial Reasoning. The following figure illustrates the training dynamics of 3D-RFT on the spatial reasoning task. Despite minor fluctuations, both evaluation accuracy and training rewards exhibit upward trends, confirming RFT's efficacy. Notably, the curves show a sign of saturation after 4000 steps. We attribute this to the nature of the optimization landscape: unlike perception tasks where RFT continuously refines continuous geometric coordinates, the reasoning task features a discrete text space with coarser feedback. This leads to the earlier saturation than 3D perception tasks, and potentially limits the granularity of improvement over SFT.
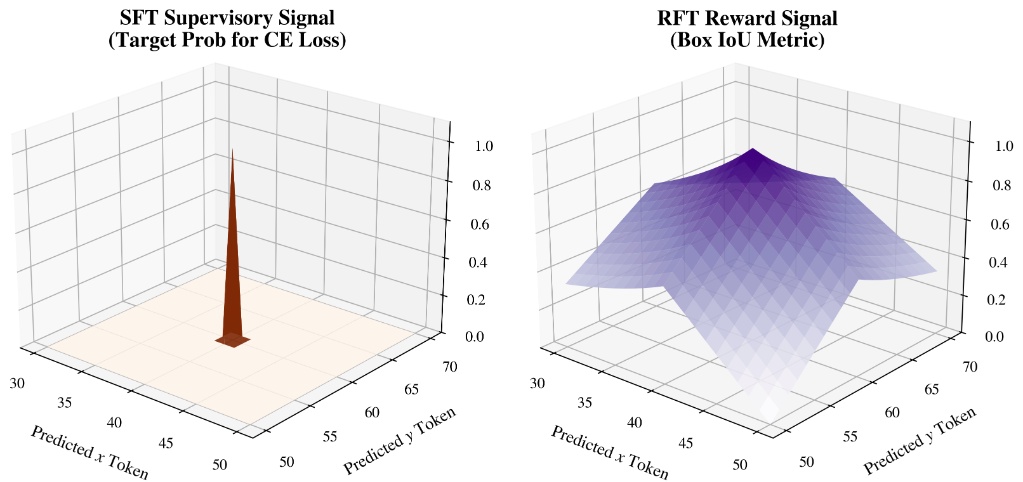
Objective landscapes of SFT and RFT. SFT supervises discrete output tokens with cross-entropy, producing a sharp target signal around the exact ground-truth token sequence. For 3D box prediction, this token-level signal is only an indirect proxy for geometric quality. RFT instead uses the decoded box IoU as a verifiable reward, yielding a smoother metric-aligned landscape where nearby 3D predictions receive meaningful partial credit.
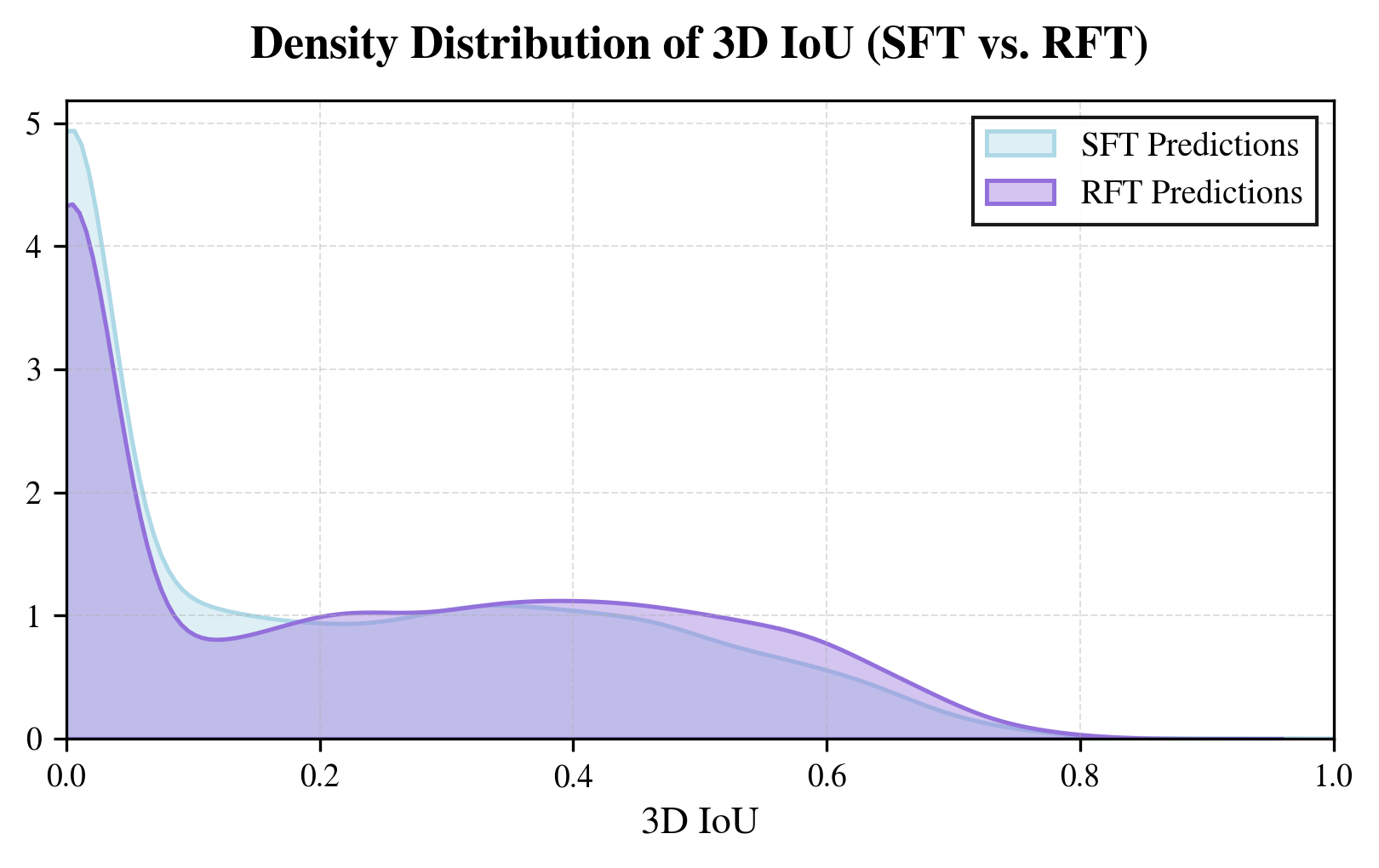
Prediction distribution shift from SFT to RFT. The density distribution of 3D IoU shows that RFT shifts predictions toward higher-overlap regions compared with the SFT baseline. This supports the core motivation of 3D-RFT: direct reward optimization encourages geometrically better predictions beyond token imitation.
If you find our model helpful, feel free to cite it:
@inproceedings{linghu20263d,
title={3D-RFT: Reinforcement Fine-Tuning for Video-based 3D Scene Understanding},
author={Linghu, Xiongkun and Huang, Jiangyong and Jia, Baoxiong and Huang, Siyuan},
booktitle={Proceedings of the International Conference on Machine Learning},
year={2026}
}